grabbing info from wikipedia
< Next Topic | Back to topic list | Previous Topic >
Posted by Pierre Paul Landry
Nov 5, 2008 at 04:00 PM
$Bill wrote:
>I have
>managed to grab a copy in InfoQube but the copy does not have “live” hyperlinks which I
>would like. (Although with some effort I could edit the HTML and find them..)
>
>I need
>to manually make a Wiki entry to
>have the Item in the grid link to the page I copied, right?
All I did, was
1- copy the main wikipedia url to the clipboard
2- Hit the IQ hotkey (mine is Win-N)
3- Enter some item description (in this case Wiki test)
4- Paste into the URL textbox
5- Check Copy Content (if not already checked). I also like to capture in MHT format, though HTML is another option. There are more options you can choose (where it goes, give it a due date, etc)
6- Click Add Item
All hyperlinks work, including the show/hide in the top-right corner!
@quant
What exactly did you select? I selected the 4 main information boxes and it clipped correctly (in IQ)
Posted by quant
Nov 5, 2008 at 04:37 PM
Pierre Paul Landry wrote:
>@quant
>What exactly did you select? I selected the 4 main information
>boxes and it clipped correctly (in IQ)
Today’s featured article
Posted by Pierre Paul Landry
Nov 5, 2008 at 05:19 PM
I updated the screenshots page to include one with just a section of the page:
http://sites.google.com/site/infoqube/screenshots-1
Posted by Chris Thompson
Nov 5, 2008 at 05:47 PM
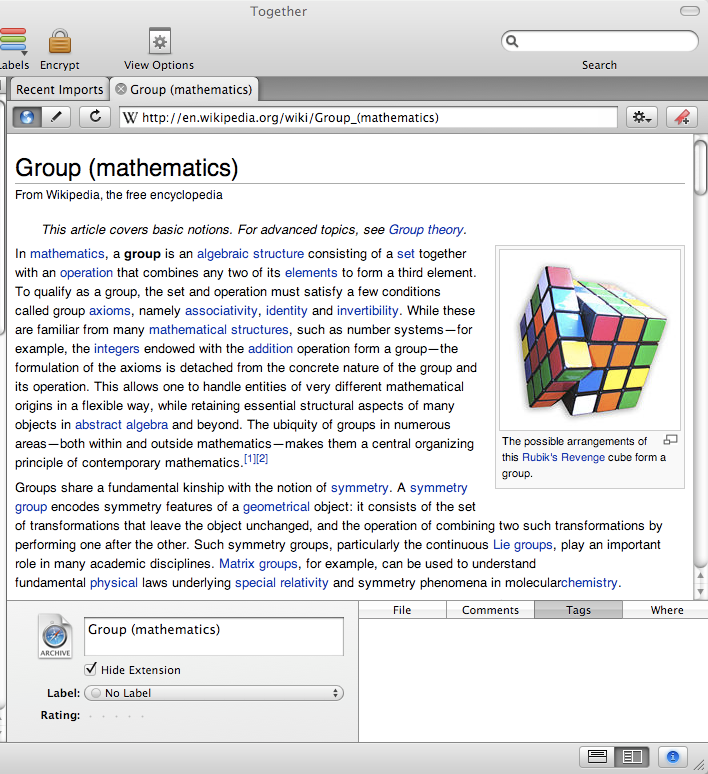
Selecting just the main part of a Wikipedia page and capturing it works in Together (and probably most Mac PIMs since they share a common engine):
http://i481.photobucket.com/albums/rr174/cthomp777/Wikipediacapture.png
{kind=link}
—Chris
quant wrote:
>The thing is that I want to save only part of the
>website, the one that contains “meat”, I don’t want the panel on the left side. But if I
>choose only part of the web, the empty space on the left side is still there (and on top as
>well), taking valuable space, and the extracted page then looks horrible in my PIM
>(because there is not enough space if I have my explorer open on the left
>side):
>http://img26.picoodle.com/img/img26/3/11/5/f_0440m_b1ce642.jpg
Posted by LW
Nov 5, 2008 at 06:11 PM
WebResearch (Macropool) does a good job capturing Wikipedia pages.